
The Illusion of Just Knowing
Introducing AI/ML in your business emphasizes the importance of data for understanding business operations and driving growth. Relying on assumptions hinders progress and creates an illusion of competence. The document advocates metrics, experimentation, and the scientific method to create a data-driven approach to doing business.

Transformative Data Pipelines for Analytics Using AWS Glue
Practical considerations for building analytics-ready data pipelines and data products using AWS Glue with Jupyter notebooks, Python, and Terraform.
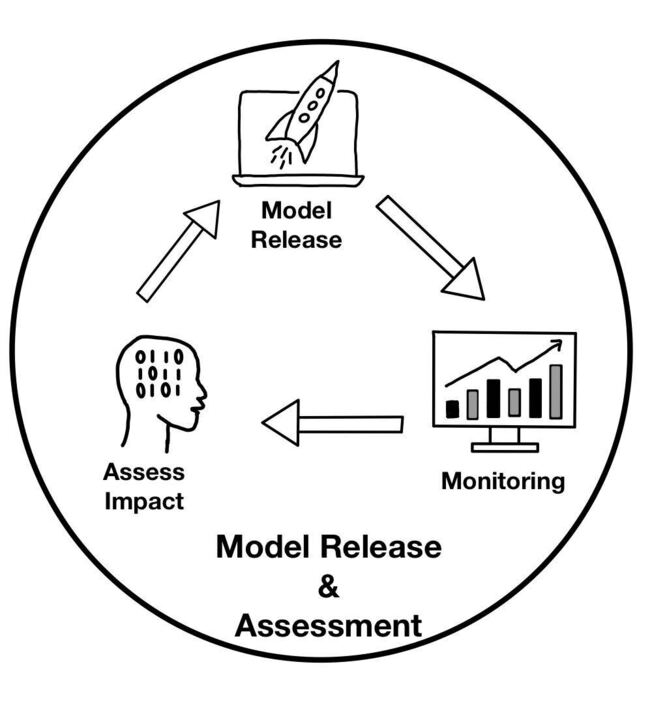
Model Release & Assessment Phase
This 3rd phase of our Data Science Process explores the release of ML models into production and the importance of ongoing monitoring and assessment.
Additionally, it provides a framework for defining "done" and achieving a high-quality model release.

Question Formation and Data Analysis in Data Science
This blog post focuses on the first phase of our Data Science Process: Question Formation and Data Analysis. In this phase, we iterate multiple times through question formation, data collection, and exploration. Initial questions are likely to be of low fidelity. Through the process of data exploration, the questions gain fidelity and drive toward business value.

Introducing a Data Science Process for AI/ML
This is an introduction to a series of blog posts describing the process of creating and operating data models in support of your AI/Machine Learning (ML) programs. It is structured to ensure that you can deliver actual business value.